数据类型
RedisObject
typedef struct redisObject {
unsigned type:4; // 对象类型(String、List、Hash 等)
unsigned encoding:4; // 数据编码方式(int、embstr、raw 等)
unsigned lru:LRU_BITS; // LRU 时间戳或 LFU 计数
int refcount; // 引用计数
void *ptr; // 指向具体存储数据的指针
} robj;
这个是所有类型的基本类型, 使用type表示具体类型, ptr指向数据, encoding表示编码格式
String
当存储的是整数时, encoding为int
当存储的是字符串, 字符串长度 <= 44 字节, encoding为 embstr 短字符串
当存储的是字符串, 字符长度 > 44 字节, encoding为 raw
embstr和raw都采用SDS存储, embstr适合短字符串, 对RedisObject和String只需要分配一次内存, embstr适合只读, 当修改时会将embstr转为raw
List
ziplist
ziplist结构:
+----------+------------+-----------+------------+------------+---------+
| zlbytes | zltail | zllen | entry1 | entry2 | zlend |
+----------+------------+-----------+------------+------------+---------+entry结构:
+------------+-----------+---------+
| prev_len | encoding | content |
+------------+-----------+---------+pre_len: 记录前一个entry长度
encoding:
- 当存储的是字符串时, encoding存储字符串长度, 用于快速获取字符串
- 当存储的时整数时, encoding存储的时整数的编码类型, 例如
int
content: 存储实际数据
优点:
- 不使用指针等额外空间实现紧凑数据类型, 节约内存
- 获取下一个地址:
next_entry = 当前 entry 起始地址 + 当前 entry 的总长度 - 获取上一个地址:
prev_entry = 当前 entry 起始地址 - prev_entry_len
- 获取下一个地址:
缺点:
-
ziplist 新增某个元素或修改某个元素时,可能会导致后续元素的 prevlen 占用空间都发生变化,从而引起连锁更新问题
-
在 ziplist 里新增或修改数据,ziplist 占用的内存空间还需要重新分配
listpack
listpack结构
+------------+-----------+------------+------------+---------+
| total_bytes| size | element1 | element2 | ... | end |
+------------+-----------+------------+------------+---------+total_bytes: 4个byte
size: 2个byte
end: 1个byte
entry结构
+----------------+------------+---------+
| encoding+length | data | backlen |
+----------------+------------+---------+encoding:
- 当存储的是字符串时, encoding存储的是字符串长度
- 当存储的是整数时, encoding直接将整数存储在encoding中, 而不需要访问data部分
data: 存储字符串的字节数组
backlen: 存储encoding和data在内的总字节数, 用于向前遍历
优点:
- 避免像ziplist的连锁更新问题
向后遍历:
-
跳过
listpack头部(共 6 字节)。 -
指向第一个
entry,读取encoding,获取encoding信息。 -
解析
encoding,确定数据类型和长度。 -
访问
data(如果是整数,则直接解析encoding,否则读取data)。 -
计算当前
entry总大小(entry-header + entry-data + entry-backlen)。 -
跳转到下一个
entry,重复步骤 2~5,直到遇到lp_end(0xFF 结束符)。
反向遍历:
- 先根据total_bytes跳到最后
- 访问最后一个entry的backlen, 然后向前backlen个长度
- 访问当前entry信息
- 向前移动指针, 再访问前一个entry的backlen
- ....
quicklist
将多个ziplist利用指针连接起来, 不仅减少了指针的数量, 还方便数据插入
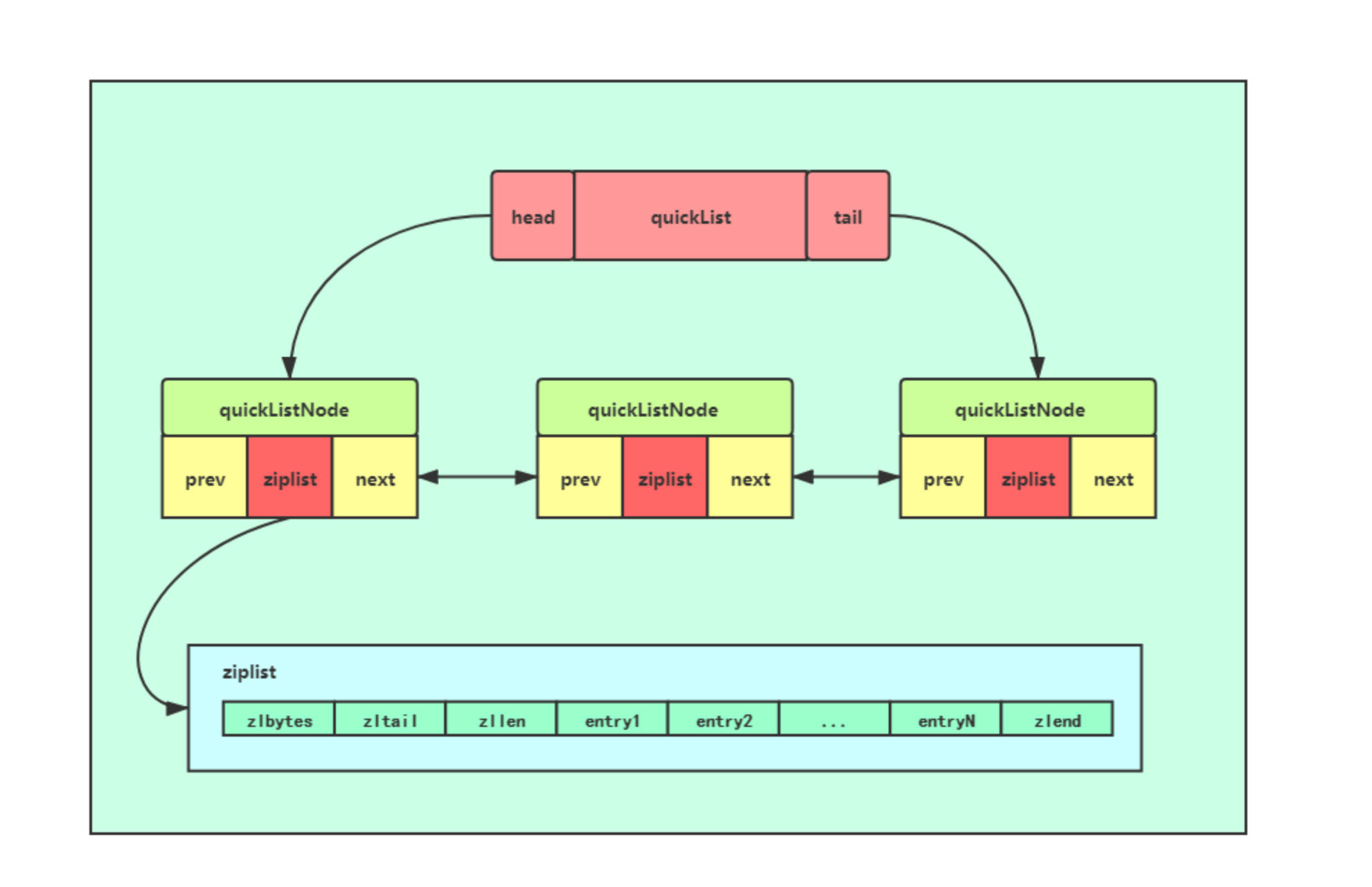
在以后的Redis版本中抛弃ziplist采用listpack
Hash
listpack: 元素个数小于 512 个
哈希表: 大于 512
Set
整数集合: 元素个数小于 512 个
哈希表
Zset
listpack: 元素个数小于 128 个,并且每个元素的值小于 64 字节时
skiplist: 不满足以上条件
skiplist不仅维护了一个链表, 还有一个dick字典用于映射member -> score
跳表
怎样才能维持相邻两层的节点数量的比例为 2 : 1 呢?
在新增数据时, 通过生成随机数, 随机决定将数据添加到上层索引
在删除数据时, 从最高层遍历查找, 只删除数据, 而不调整结构
总体维持在2:1
为什么使用跳表而不是平衡树
-
对于平衡树,每个节点一定使用2个指针, 对于跳表每个节点平均使用1.33个指针(包含索引节点, 索引节点只有一个指针, 因为不用做真正的数据返回), 所以跳表占用更少内存
-
跳表范围查询例如
zrange或者zrevrange时, 更简单, 平衡树需要中序遍历 -
在插入或者删除数据时会导致平衡树自旋, 跳表只需要修改指针
BitMap
底层利用String, 因为String的存储利用了字节数组, bitmap将每个bit位利用起来, 所以一个字节可以表示8个bit位